

Every machine learning project is built on the back of copious volumes of data. It’s not just any data, either, but data that are prepared specifically for use in model training. For the most common approaches to ML model development in business—supervised learning—means carrying out data annotation.
Data annotation involves taking pieces of training data and adding further information—or metadata—to them, which helps the model make sense of them.
This metadata provides valuable context, labels, or descriptors, guiding the model’s analysis. While this can be automated, it’s usually entrusted to people since expertise and certainty are important to the labeling process.
Annotation is one of the most time-consuming parts of preparing data, though, which makes outsourcing it an appealing prospect. Outsourcing data annotation can save time and reduce costs while ensuring precision in the training data. In this article, we’ll go over some aspects of data annotation that are easily outsourced and how you can do so for your own ML models.
- Data annotation involves taking pieces of training data and adding further information—or metadata—to them, which helps the model make sense of them. This metadata guides the model’s analysis.
- Major challenges in data annotation include the sheer volume of information that goes into making a data set and maintaining consistency across all that data.
- Outsourcing data annotation can be a cost-saving measure as well as a strategic choice to pursue business objectives.
What is Data Annotation?
Data annotation is a method of preparing data for data for machine learning model training.
In annotation, metadata is attached to individual data objects which add meaning and structure to them. The metadata takes the form of labels, which might mark relevant attributes such as category, location, time,
Under supervised learning, the model then uses this metadata to create patterns and, later, judgments or predictions. Data annotation also makes it easier for people to sort through data sets, since these tags or labels make it easier to sort and identify data points.
Annotation can be applied to various types of training data. For example:
- Text annotation is the most common, as most ML models for business use text. The text might be labeled with notes in context, mood, or intention, among other things.
- Image annotation may involve labeling specific objects within a picture. It could also involve noting the presence or absence of certain elements in images and videos.
- Audio material can be annotated like text or marked for the presence of certain sonorous elements, like instruments, specific voices, and so on.
Whatever the medium of the data, annotation can provide a basis for classifying it, making it easier to use, group, and retrieve.

What is Data Annotation Outsourcing?
One major challenge in annotation is the sheer volume of information that goes into making a data set. Maintaining precision across so many data points can be taxing, especially for teams that can’t dedicate themselves to such data preparation.
For this reason, data annotation outsourcing is an increasingly common practice among businesses developing or adapting ML tools. In this setup, an external team is provided with the objectives and framework for annotation, then set to work on the training data.
Data annotation services generally provide a certain rate of output over time, with services that can be scaled to match the scope of the model in development.
Human-in-the-Loop AI
If you look into outsourcing AI development or model training, you’ll quite likely come across the term “human in the loop” (HITL). This refers to the practice of involving human activity at various points of the training process. These include data preparation, classification or categorization, evaluating results, and deliberate testing.
HITL is widely seen as an efficient, accessible means of training or retraining ML models while ensuring more reliable results with minimal bias.

Benefits of Outsourcing Data Annotation
Outsourcing data annotation can be a cost-saving measure as well as a strategic choice to pursue business objectives.
Saves Time and Resources
Data annotation companies provide quality output at costs lower than you’d get with an in-house team. Offshore annotation services, in particular, can offer truly competitive rates. You also gain access to consistent services without the need to cover office space, benefits or other overhead costs.
Provides Scalability and Flexibility
You can scale outsourced operations up or down as needed. This is useful for projects with seasonal or cyclical demands. It’s also great for testing out new projects: you can have a proof of concept project deployed much quicker.
Focus on Core Competencies
Outsourcing means keeping your team free to focus on their own specializations. It also means you’re not bogged down by recruitment and onboarding.
More Accurate AI Predictions
Dedicated outsourcing providers will be up-to-date with best practices and industry-standard tools to ensure reliable annotation. Working with a reputable partner guarantees high-quality training data and, therefore, accurate predictions.
Reduces Bias
Bias from data or existing systems can influence an ML model during training. Having a team to double-check both data sets and results can mitigate bias, which might otherwise have harmful consequences.
Data Annotation Tasks You Can Outsource
Annotation can be directed toward certain objectives or broken down into a variety of more specific tasks. Here are some specific examples of tasks you can outsource.
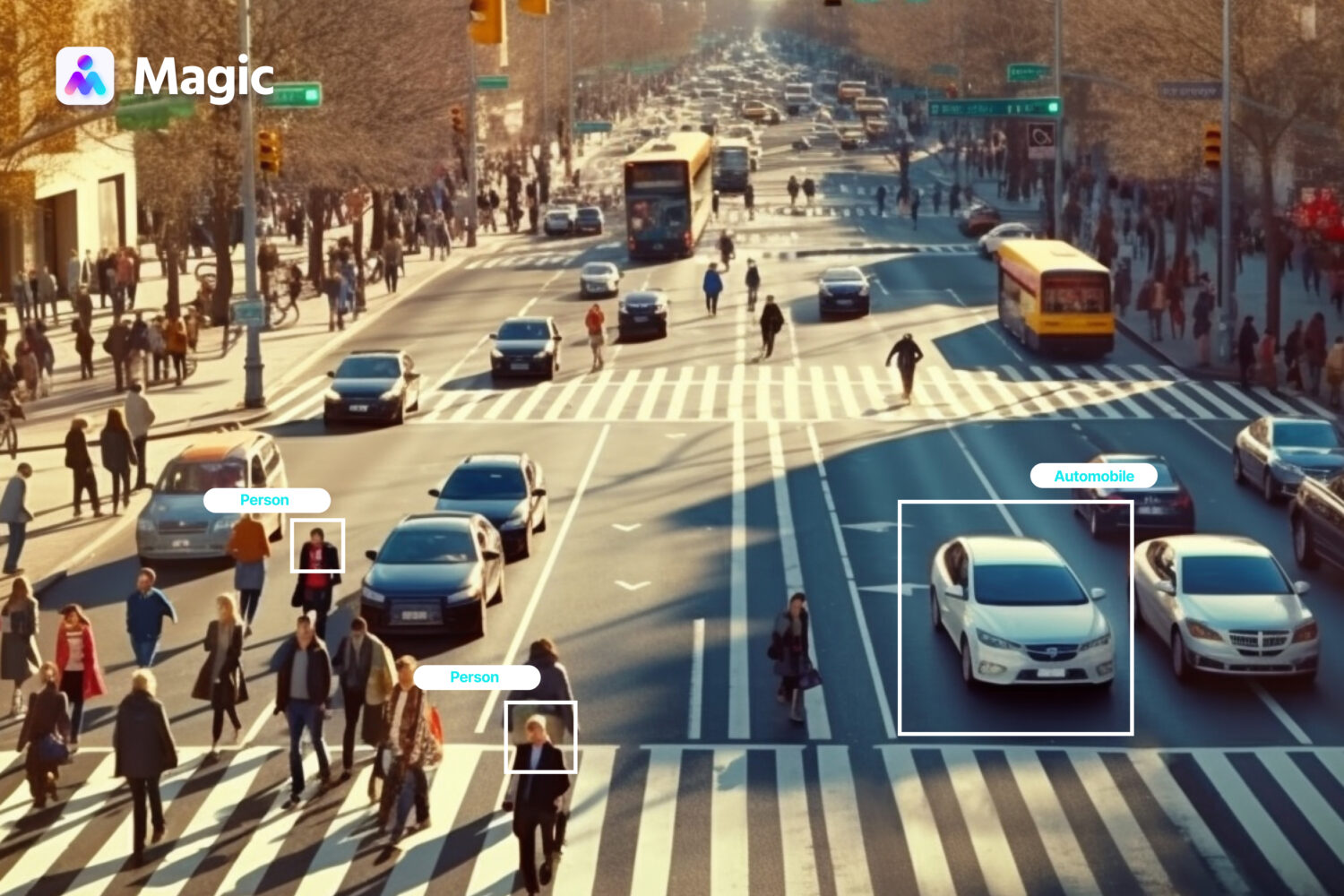
Object Detection
Object recognition is an ML application that is in widespread use among businesses. Developing an object detection tool, however, requires especially large data sets annotated with utmost consistency.
Every instance of every object you want the tool to identify must be labeled accordingly. Outsourcing is one feasible way to get data points in the required quantities.
Sentiment Analysis
Machines can’t recognize emotion or tone the way humans do, but they can be trained to recognize certain sentiments based on patterns of language. You can label textual statements according to their sentiments, using your choice of classification—whether a simple divide of positive-negative or more complex groupings.
Intent Annotation
As with sentiment, ML models can be trained to analyze intent based on patterns in text. By establishing categories of intention—such as requests, questions, recommendations or purchase inquiries—you can train a model to recognize what a person intends, in addition to other contents of their posts or messages.
Semantic Segmentation
Semantic segmentation is a function that divides a given input into segments or bounding boxes, based on the type of object occupying each of those segments.
To provide an example: a still-life painting could be semantically segmented into varying types of fruit, their containers, and background elements—each identified and cordoned off into the space it occupies.
This sort of automation relies on extensively annotated data sets, identifying the contents of input as well as their locations within each data point.
Image Classification
Alternatively, models can be trained to sort or classify images in their entirety, using overall qualities or characteristics. In this case, images may be annotated for the defining features of the categories you’re establishing.
Named Entity Recognition
Named Entity Recognition (NER) identifies specific mentions of names within texts, and then classifies or labels them based on the nature of their referent.
For example, an NER tool might extract instances of the names of people and label them “person”, or scan for company names and label them “company”—or some more specific type of business. It’s a useful function for extracting ordered information from unstructured text, which can then be entered into databases or put to similar use.
NER requires large quantities of annotated training data. Outsourcing it can bring it within reach of even smaller businesses.

Through human-in-the-loop outsourcing, skilled workers can improve the speed, precision, and reliability of AI tools.
Learn More
Getting Started on Data Annotation Outsourcing
If you’re not certain about where or how to start outsourcing data annotation, you can begin with a few main considerations.
- Objectives. How much work do you need done? If you don’t have a fixed end goal, start with an initial figure or rate: how much you need labeled per week or month, how many and what sorts of annotation, and so on.
- Budget and Constraints. How much funding and management time can you dedicate to the project or to working with the outsourced team? If you have less time to look into it, you may need a fully managed service.
- Scalability. Do you need this for a single project? Will its scope ramp up as you go? If your requirements may change, consider how flexible your chosen vendors might be.
- Benchmarking. Consistency is crucial to data annotation. Before you wholly entrust annotation to a third-party service provider, it’s a good idea to benchmark some of their early work against a standard you can trust in. If you’re dealing with fairly conventional annotation, you might be able to find a fairly reliable automated annotation benchmark. Alternatively, an expert from within your business—or you yourself—can annotate some data and use that as a point of reference for their work.

Magic’s Data Annotation Services
Data annotation is a necessary step in the typical AI model development process. Outsourced data annotation services are a cost-effective method of preparing training data for your own custom tools. Better still, it can be scaled up or down to match your constraints and objectives.
Magic can get you a remote team to handle data annotation as well as other HITL AI training tasks, like transcription and evaluation. Just tell us what skills you need in your remote staff, and we’ll find the right candidates for you within a week.
You can easily customize your remote team as you see fit. You can adjust schedules and modify or expand your team—including adjacent roles such as virtual admin work—with a message.
Talk to us to get started.
